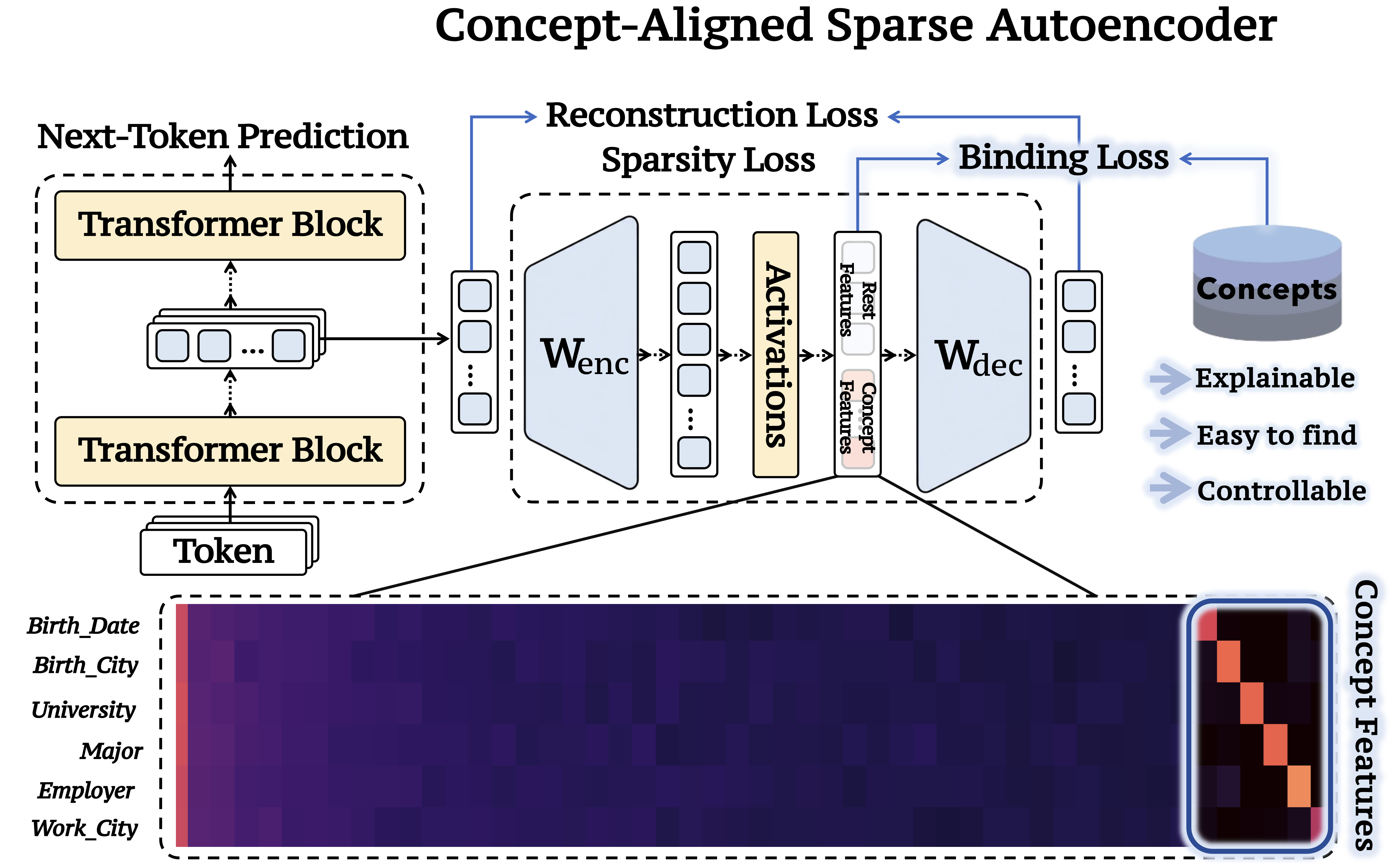
Large Language Models (LLMs) encode factual knowledge within hidden parametric spaces that are difficult to inspect or control. While Sparse Autoencoders (SAEs) can decompose hidden activations into more fine-grained, interpretable features, they often struggle to reliably align these features with human-defined concepts, resulting in entangled and distributed feature representations. To address this, we introduce AlignSAE, a method that aligns SAE features with a defined ontology through a "pre-train, then post-train" curriculum. After an initial unsupervised training phase, we apply supervised post-training to bind specific concepts to dedicated latent slots while preserving the remaining capacity for general reconstruction. This separation creates an interpretable interface where specific relations can be inspected and controlled without interference from unrelated features. Empirical results demonstrate that AlignSAE enables precise causal interventions, such as reliable "concept swaps", by targeting single, semantically aligned slots.
@misc{yang2025alignsaeconceptalignedsparseautoencoders,title={AlignSAE: Concept-Aligned Sparse Autoencoders},author={Yang, Minglai and Guo, Xinyu and Bi, Jinhe and Bethard, Steven and Surdeanu, Mihai and Pan, Liangming},year={2026},eprint={2512.02004},archiveprefix={arXiv},primaryclass={cs.LG},url={https://arxiv.org/abs/2512.02004},google_scholar_id={Tyk-4Ss8FVUC},}
ArXiv
Peeking inside the Black-Box: Reinforcement Learning for Explainable and Accurate Relation Extraction
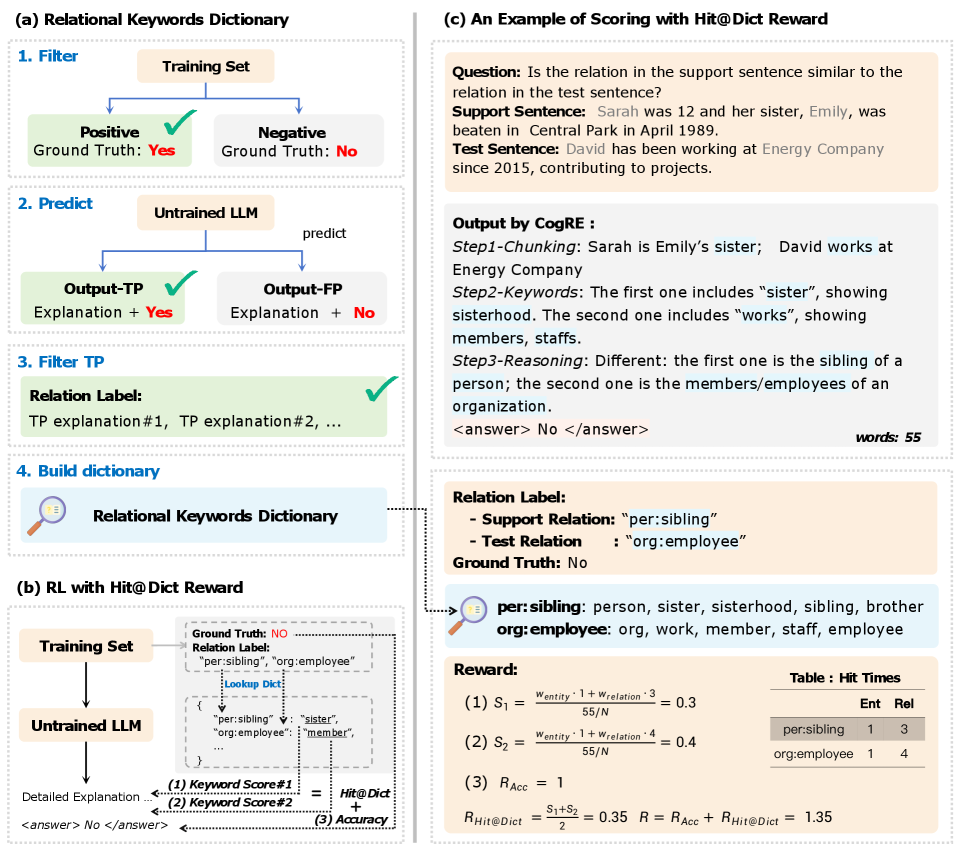
This paper introduces a framework for relation extraction (RE) that enhances both accuracy and explainability. The framework has two key components: (i) a reasoning mechanism that formulates relation extraction as a series of text-processing steps inspired by cognitive science, and (ii) an optimization process driven by reinforcement learning (RL) with a novel reward function designed to improve both task accuracy and explanation quality. We call our approach CogRE. Our framework addresses the lack of supervision for language-based explanations in traditional RE by promoting outputs that include important relation keywords. These keywords are drawn from a high-quality dictionary that is automatically constructed using an LLM. We evaluate our approach for the task of one-shot RE using two LLMs and two RE datasets. Our experiments show that CogRE improves explanation quality by addressing two common failure patterns in one-shot RE: poor attention focus and limited one-shot learning capability. For example, our cognitive-structured reasoning with Qwen2.5-15B-Instruct on One-shot NYT29 achieves 24.65% F1, surpassing prior reasoning-based designs. Optimizing this approach with RL using our reward further improves performance by +23.46% (absolute). Finally, human evaluation shows that our best model generates relational keywords closely aligned with gold labels, increasing human explanation quality ratings by 54% (relative).
We introduce Grade School Math with Distracting Context (GSM-DC), a synthetic benchmark to evaluate Large Language Models’ (LLMs) reasoning robustness against systematically controlled irrelevant context (IC). GSM-DC constructs symbolic reasoning graphs with precise distractor injections, enabling rigorous, reproducible evaluation. Our experiments demonstrate that LLMs are significantly sensitive to IC, affecting both reasoning path selection and arithmetic accuracy. Additionally, training models with strong distractors improves performance in both in-distribution and out-of-distribution scenarios. We further propose a stepwise tree search guided by a process reward model, which notably enhances robustness in out-of-distribution conditions.
@article{yang2025llmreasoningdistractedirrelevant,title={How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark},author={Yang, Minglai and Huang, Ethan and Zhang, Liang and Surdeanu, Mihai and Wang, William and Pan, Liangming},year={2025},eprint={2505.18761},archiveprefix={arXiv},primaryclass={cs.CL},url={https://arxiv.org/pdf/2505.18761},google_scholar_id={UeHWp8X0CEIC},}
We introduce CopySpec, a simple yet effective technique to tackle the inefficiencies LLMs face when generating responses that closely resemble previous outputs or responses that can be verbatim extracted from context. CopySpec identifies repeated sequences in the model’s chat history or context and speculates that the same tokens will follow, enabling seamless copying without compromising output quality and without requiring additional GPU memory. To evaluate the effectiveness of our approach, we conducted experiments using seven LLMs and five datasets: MT-Bench, CNN/DM, GSM8K, HumanEval, and our newly created dataset, MT-Redundant. MT-Redundant, introduced in this paper, transforms the second turn of MT-Bench into a request for variations of the first turn’s answer, simulating real-world scenarios where users request modifications to prior responses. Our results demonstrate significant speed-ups: up to 2.35x on CNN/DM, 3.08x on the second turn of select MT-Redundant categories, and 2.66x on the third turn of GSM8K’s self-correction tasks. Importantly, we show that CopySpec integrates seamlessly with speculative decoding, yielding an average 49% additional speed-up over speculative decoding for the second turn of MT-Redundant across all eight categories. While LLMs, even with speculative decoding, suffer from slower inference as context size grows, CopySpec leverages larger contexts to accelerate inference, making it a faster complementary solution. Our code and dataset are publicly available at https://github.com/razvandu/copyspec.
@article{dumitru2025copyspecacceleratingllmsspeculative,title={CopySpec: Accelerating LLMs with Speculative Copy-and-Paste Without Compromising Quality},author={Dumitru, Razvan-Gabriel and Yang, Minglai and Yadav, Vikas and Surdeanu, Mihai},year={2025},eprint={2502.08923},archiveprefix={arXiv},primaryclass={cs.CL},url={https://arxiv.org/abs/2502.08923},google_scholar_id={u-x6o8ySG0sC},}
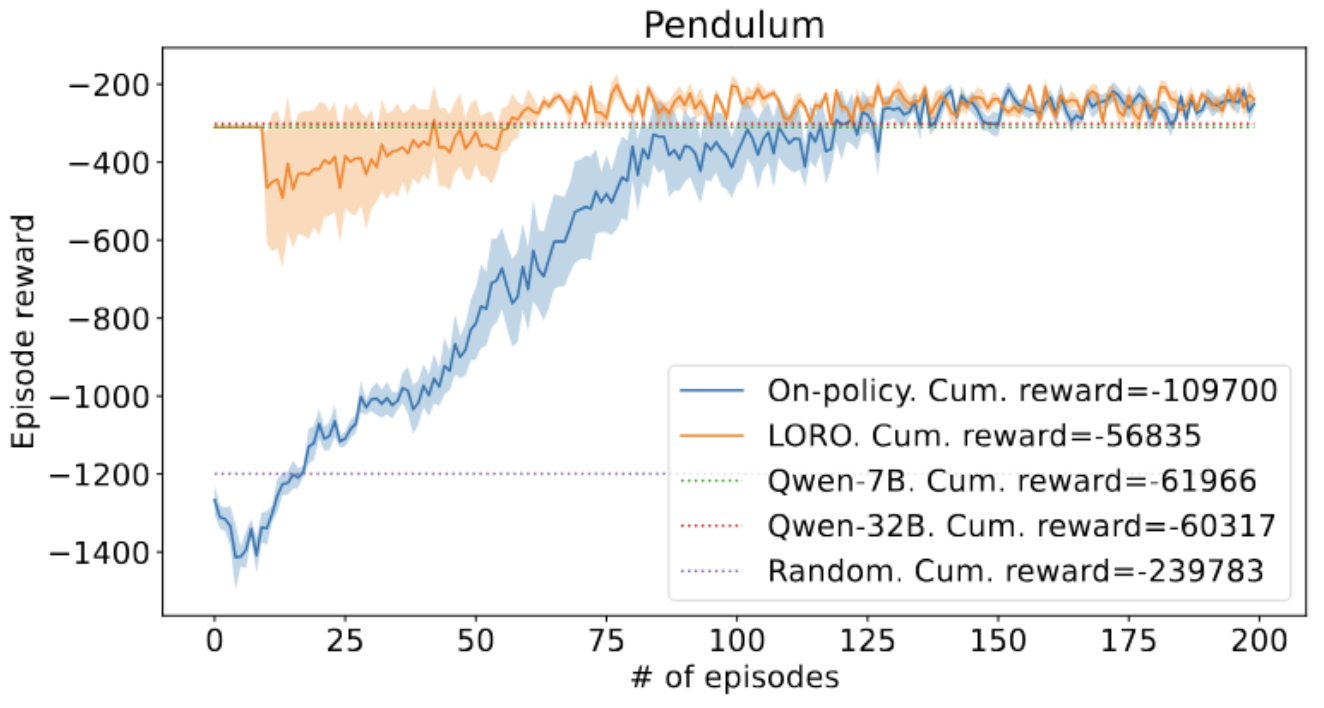
We investigate the usage of Large Language Model (LLM) in collecting high-quality data to warm-start Reinforcement Learning (RL) algorithms for learning in some classical Markov Decision Process (MDP) environments. In this work, we focus on using LLM to generate an off-policy dataset that sufficiently covers state-actions visited by optimal policies, then later using an RL algorithm to explore the environment and improve the policy suggested by the LLM. Our algorithm, LORO, can both converge to an optimal policy and have a high sample efficiency thanks to the LLM’s good starting policy. On multiple OpenAI Gym environments, such as CartPole and Pendulum, we empirically demonstrate that LORO outperforms baseline algorithms such as pure LLM-based policies, pure RL, and a naive combination of the two, achieving up to 4\times the cumulative rewards of the pure RL baseline.
@article{duong2025improvingdataefficiencyreinforcementlearning,title={Improving the Data-efficiency of Reinforcement Learning by Warm-starting with LLM},author={Duong, Thang and Yang, Minglai and Zhang, Chicheng},year={2025},eprint={2505.10861},archiveprefix={arXiv},primaryclass={cs.LG},url={https://arxiv.org/abs/2505.10861},google_scholar_id={d1gkVwhDpl0C},}
2024
MCM
Dynamic Balances: Modelling Variable Sex Ratios in Lamprey Populations for Ecosystem Management
M.
Yang, M.
Abbasi, and S.
Soporboev
Best Paper at University of Arizona Math Modeling
International Mathematical Contest in Modeling (MCM)., Tucson, Arizona. ** The Problem can be found here
, May 2024
We developped an Adaptive Population Control (ACC) model that explains the skewed sex ratio at high and low levels of resource availability as a control measure by lamprey to maximize their growth rate. We find that the advantage of a variable sex ratio is greatest under extremely poor or extremely suitable environmental conditions. Next, to account for the male skewed populations of lamprey at high densities, we develop a modified logistic growth model that allows for variable carrying capacity for males and females. Differential Carrying Capacity (DCC) model accurately predicts the optimal sex ratio to achieve the maximal growth rate at various population densities. In line with ACC, we use Aquatic Nutritional Network (ANN), a niche width differential equation model is developed by integrating concepts from Lotka-Volterra equations. to study the dynamics of lamprey and their native prey/predator. We find that variable sex ratios allow time for regeneration of the native prey in Lamprey.

 Dynamic Balances: Modelling Variable Sex Ratios in Lamprey Populations for Ecosystem ManagementBest Paper at University of Arizona Math ModelingInternational Mathematical Contest in Modeling (MCM)., Tucson, Arizona. ** The Problem can be found here , May 2024
Dynamic Balances: Modelling Variable Sex Ratios in Lamprey Populations for Ecosystem ManagementBest Paper at University of Arizona Math ModelingInternational Mathematical Contest in Modeling (MCM)., Tucson, Arizona. ** The Problem can be found here , May 2024